
Start Sieci jednokierunkowe Sieci rekurencyjne Słowniczek Linki O autorach
Reguły uczenia
Wprowadzenie
Jedną z istotnych niedogodności metod propagacji wstecznej i MRII jako sposobów uczenia sieci neuronowej jest to, że wymagają one "nauczyciela", którego zadaniem jest podawanie dla każdego wektora wejściowego wzorcowego wektora oczekiwanej odpowiedzi sieci. Układ biologiczny, jakim jest mózg, uczy się jednak bez pomocy nauczyciela, rozpoznając świat na podstawie wrażeń zmysłowych baz żadnych bezpośrednich instrukcji.
Wielu badaczy, zwłaszcza tych, którzy posługują się SSN w celu zrozumienia procesów zachodzących w sieciach biologicznych, podjęło się zadania opracowania sieci, która potrafiłaby wykorzystać informacje zawarte w dużym zestawie wzorców, będąc pozbawioną wiedzy a priori o tym, co one reprezentują. Sieć powinna "odkryć" bez zewnętrznej pomocy wzory, cechy, wzajemne zależności, uporządkowanie danych wejściowych, a następnie podać te informacje w odpowiednio zakodowanej postaci na wyjście.
Uczenie "bez nauczyciela", zwane też nienadzorowanym, jest możliwe wówczas, gdy mamy do czynienia z redundancją (nadmiarowością) danych wejściowych. Bez tej cechy obrazów uczących byłoby niemożliwe wyodrębnienie z nich wzorców, czy też rozpoznanie ich cech. Aby sieć mogła pracować bez zakłóceń, powinna istnieć możliwość podziału zbioru obrazów wejściowych na rozłączne klasy, według dobrze określonych cech wspólnych. Sieć powinna być zdolna do zidentyfikowania wspomnianych wspólnych cech w dowolnym prezentowanym wektorze wejściowym.
Reguła Hebba
Opierając się na zasadzie tworzenia się odruchów warunkowych, Hebb wprowadził następującą zasadę. Jeśli aktywny neuron A jest cyklicznie pobudzany przez neuron B, to staje się on jeszcze bardziej czuły na pobudzenie tego neuronu. Jeśli przez xA i xB oznaczymy stany aktywacji neuronów A i B, a przez wAB - wagę ich połączenia synaptycznego, to powyższą regułę można zapisać w postaci następującego równania:
gdzie a oznacza pewną stałą dodatnią, sterującą procesem uczenia.
Reguła Hebba posiada istotną wadę, mianowicie prowadzi do procesu rozbieżnego. Aby to udowodnić, rozważmy liniowy element przetwarzający. Jego stan aktywacji x w chwili k jest równy:
gdzie w(k) oznacza wektor wag wejściowych połączeń synaptycznych elementu, u(k) - wektor wejściowy należący do pewnego zbioru G wektorów uczących, wzięty z tego zbioru zgodnie z rozkładem prawdopodobieństwa, oraz podany na wejście elementu w chwili k-tej.
Zgodnie z ogólną regułą kolejne prezentacje wzorców ze zbioru G zmieniają wektor wag o przyrost DW(k) określony zależnością:
Dalej będziemy zakładać, że elementy ciągu íu(k)ý są niezależne (tzn. wynik losowania wzorca ze zbioru G w danej chwili nie zależy od wyników losowań w innych chwilach). Warunkiem zbieżności procesu uczenia jest zerowanie się (od pewnego momentu) średniej zmiany wag:
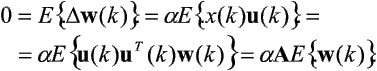
gdzie:
jest macierzą korelacji obrazów wejściowych, a Eí.ý operatorem wartości oczekiwanej.
Zgodnie z definicją macierz A jest macierzą symetryczną. Ponadto można wykazać, że jest dodatnio półokreślona, gdyż:
Wynika stąd, że wszystkie jej wartości własne są rzeczywiste i nieujemne. Wektory własne odpowiadające różnym wartościom własnym są ortogonalne. Z warunku zbieżności procesu uczenia wynika, że potencjalny stan równowagi wr jest wektorem własnym a0 macierzy A odpowiadającym zerowej wartości własnej, tzn. wr = a0, gdzie Aa0 = 0. Aby przekonać się, czy stan a0 jest stanem stabilnym, wystarczy sprawdzić, czy po niewielkim zaburzeniu układ kierujący się regułą Hebba do niego powróci.
Niech wektor w(0) będzie wektorem bliskim a0, tzn. w(0) = a0 + e0, przy czym e(0) jest niewielkim zaburzeniem a0. Wartość oczekiwana wektora wag w (k + 1)-ym kroku wyraża się zależnością:
Definiując e(k) = w(k) - a0 otrzymujemy:
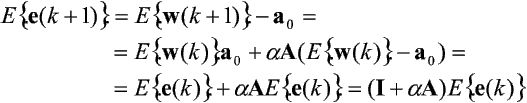
Wynika stąd zależność:
Korzystając z ortogonalności wektorów własnych macierzy A, można ją przekształcić do postaci diagonalnej Z-1AZ = D, przy czym Z jest macierzą, której kolumny są kolejnymi wektorami własnymi macierzy A, D - macierzą diagonalną, której diagonala zawiera odpowiednie wartości własne macierzy A.
Definiując:
otrzymujemy zależność:
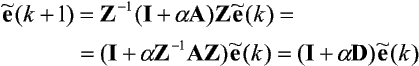
czyli:
Zauważmy, że macierz występująca po prawej stronie powyższego wzoru jest diagonalna. Dla stabilności potrzeba, aby limk®Ą Eíe(k)ý = 0 lub równoważnie limk®Ą e~(k) = 0. Stąd i z ostatniej zależności otrzymujemy warunek:
gdzie lj oznacza j-tą wartość własną macierzy A. Oczywiście warunek ten jest spełniony tylko wtedy, gdy:
Ponieważ jednak a > 0, w konsekwencji otrzymujemy warunek:
Przeczy to jednak dodatniej półokreśloności macierzy korelacji A. Z przeprowadzonego rozumowania wynika więc rozbieżność procesu uczenia według reguły Hebba.
Reguła Oja
Najprostszą metodą zapobiegania nieograniczonemu wzrostowi wartości wektora wag przy korzystaniu z reguły Hebba jest normalizacja tego wektora po każdej iteracji. Wzrasta jednak w ten sposób koszt pracy algorytmu. Można również narzucić ograniczenia dolne (wi-) i górne (wi+) na każdą z wag, tzn. wi Î [wi-, wi+]. Oja zaproponował modyfikację reguły Hebba, gwarantującą osiągnięcie stanu stabilnego w przestrzeni wag, w następującej postaci:
Badanie zbieżności tej reguły rozpoczyna się od wyznaczenia potencjalnego stanu równowagi wr procesu uczenia. Podobnie jak w przypadku reguły Hebba okazuje się, że jest nim jeden z wektorów własnych macierzy korelacji obrazów wejściowych A. Istotnie, załóżmy, że wspomniany wektor wag wr został zaburzony, tzn. w chwili początkowej mamy do czynienia z wektorem wag w(0) = wr + e(0), przy czym e(0) ą 0 jest pewnym zaburzeniem początkowym. Na podstawie podanej wyżej równości otrzymujemy zależność:
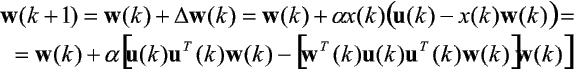
W oparciu o nią otrzymuje się następujące równanie opisujące zmiany w czasie zaburzenia e(k) = w(k) - wr:
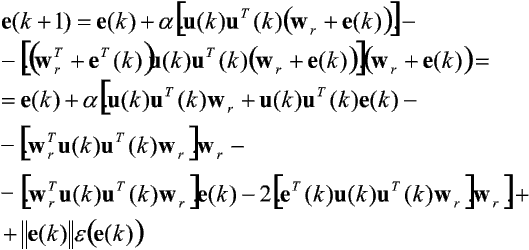
gdzie lime®0e(e(k)) = 0.
Zaniedbując w powyższym wyrażeniu ostatni składnik, oznaczający człony wyższego rzędu (innymi słowy - dokonując linearyzacji wokół punktu równowagi wr), a następnie wyznaczając wartości oczekiwane obu stron, otrzymujemy zależność:
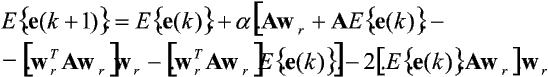
Oczywiście, w stanie równowagi (dla w(0) = wr) powinna zachodzić równość Eíe(k)ý = 0, k = 1, 2, ... . Po uwzględnieniu jej w powyższym wzorze otrzymujemy następujący związek pozwalający wyznaczyć wr:
Wynika stąd, że wr jest wektorem własnym macierzy A odpowiadającym wartości własnej lp = wrTAwr. Zauważmy ponadto, że wektor ten jest już unormowany, bowiem zachodzi:
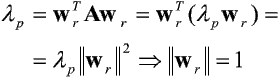
Spróbujmy teraz określić, który z wektorów własnych macierzy A jest stanem równowagi, oraz czy określa on stan równowagi stabilnej procesu uczenia. W dalszych rozważaniach wygodniej będzie używać oznaczenia ap = wr, podkreślającego, że wr jest p-tym z wektorów własnych a1, ..., aN macierzy A.
Równanie określające Eíe(k + 1)ý można teraz przepisać w postaci:
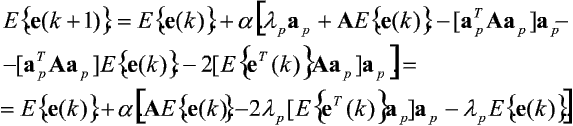
Korzystając z ortogonalności wektorów własnych macierzy A można ją przekształcić do postaci diagonalnej Z-1AZ = D. Przyjmując, że e~(k) = Z-1Eíe(k)ý, otrzymujemy:
Zauważymy, że po diagonalizacji poszczególne równania owego układu są niezależne i mają postać:
gdzie dij oznacza deltę Kroneckera.
Wynika stąd, że:
Stabilność procesu oznacza, że musi być spełniony warunek limk®Ą Eíe(k)ý = 0, lub równoważnie limk®Ą e~j(k) = 0, j = 1, ..., N. Stąd i z ostatniej zależności otrzymujemy warunek:
Wynika stąd bezpośrednio, że lp musi być maksymalną wartością własną macierzy A. Istotnie, w przeciwnym bowiem razie istniałaby inna wartość własna lq > lp, jednak wtedy byłoby:
co przeczyłoby poprzedniemu warunkowi. Spełnienie tego warunku dla j = p uzyskuje się poprzez dobór odpowiednio małej wartości współczynnika uczenia a > 0.
W powyższych rozważaniach udowodniono, że wektor wag będący wektorem własnym macierzy A należącym do jej maksymalnej wartości własnej lmax jest, w sensie średnim, stabilnym punktem stałym reguły Oja. Nie jest to dowód zbieżności procesu uczenia zgodnego z tą regułą, który może niekiedy prowadzić do ciągłych fluktuacji bądź zachowań cyklicznych.

Start Sieci jednokierunkowe Sieci rekurencyjne Słowniczek Linki O autorach